Now available as a live demo!
GitHub repo is here.
Motivation
What is the most powerful LLM that can realistically be trained for less than $100? That question led me to build a 350M-parameter model in PyTorch. I wanted to deeply understand transformer architecture, not just for LLMs but also for its broader uses in regression and multimodal systems, so I wrote the entire model from scratch. Along the way, I implemented key components such as causal masking, attention masking, loss masking, RoPE, embeddings, and KV caching directly from PyTorch primitives.
Design
The model was pretrained on the 10B token sampling of the FineWebEdu dataset. I followed the Transformer architecture sizing and hyperparameters laid out in the GPT-3 paper. I chose a context length of 2048, which meant a batch size of around 256 samples. To keep training costs under $100, I chose to use a 350M parameter model, which corresponds to the GPT-Medium size in the paper.
Training
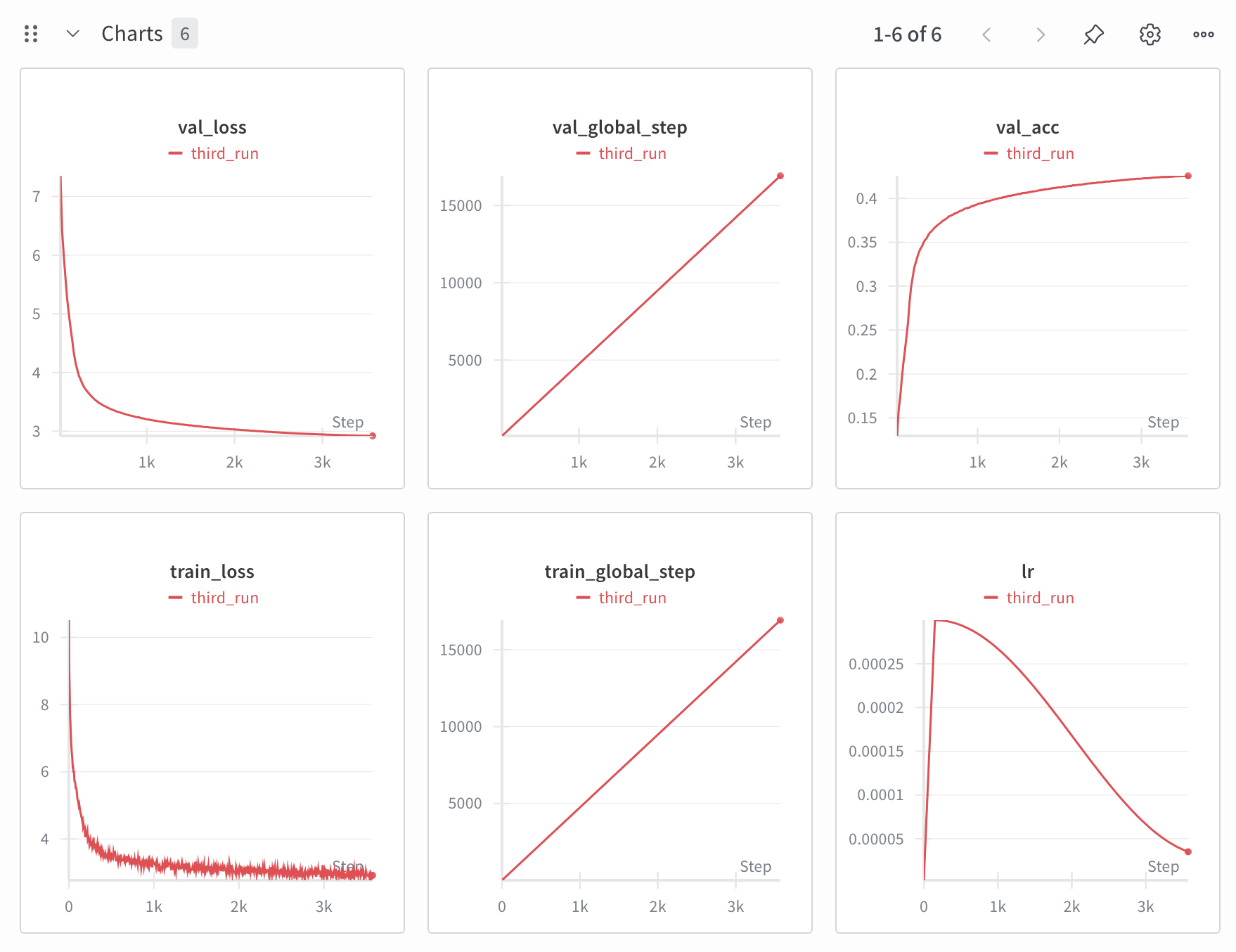
After implementing all common optimizations such as the use of tf32, bf16, torch compile, and Flash Attention. Since I pre-tokenized the training corpus before starting training, I managed to achieve 100% gpu util, leaving me with a training throughput of 30,000 tokens/sec per GPU. I was able to further improve training speed after realizing the PyTorch Flash Attention function scaled_dot_product_attention skips the fast path if an attention mask is set! I thus put a conditional statement in my transformer architecture that did not pass an attention mask (but rather only a causal mask) into the function during pretraining, which allowed it to activate the fast path and reach a training speed of 50,000 tokens/sec per GPU. The learning schedule used cosine annealing with linear warmup and a maximum learning rate of 3e-4. Pretraining completed in 55 hours. The wandb plots are shown below.
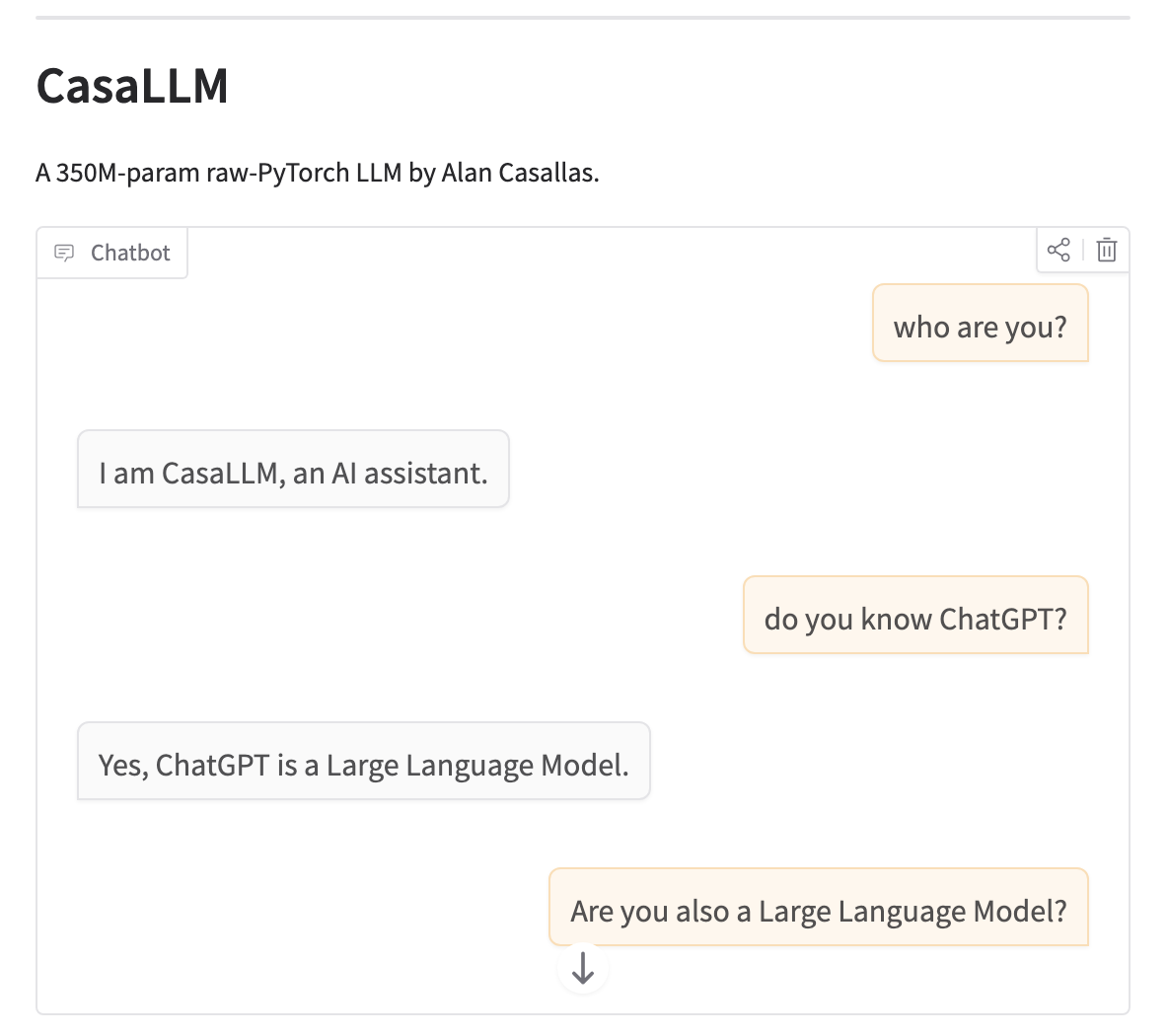
I then performed supervised fine-tuning. I used a combination of the ultrachat-200k dataset (sampled down to 50k examples) along with the 50k sample yahma/alpaca-cleaned dataset, for a total of 100k examples. All samples were formatted according to the conversation template that I selected before tokenization. I was careful to clean the dataset of any samples which might cause the LLM to incorrectly identify itself as ChatGPT, Gemini, or any other LLM. I also injected my own conversation samples to make sure my model would respond appropriately to greetings as well as to self-identification questions such as "who are you?" and "who made you?".
Fine-tuning was performed for 3 epochs of 100,000 samples using a learning schedule of cosine annealing with linear warmup with a max learning rate of 10% what the pretraining learning rate was. As can be seen from the plots below, training loss was very noisy because the training samples were of very varied length. Shorter samples especially will exhibit a large variance in loss. However, I was encouraged by the monotonically decreasing curve of the validation loss.
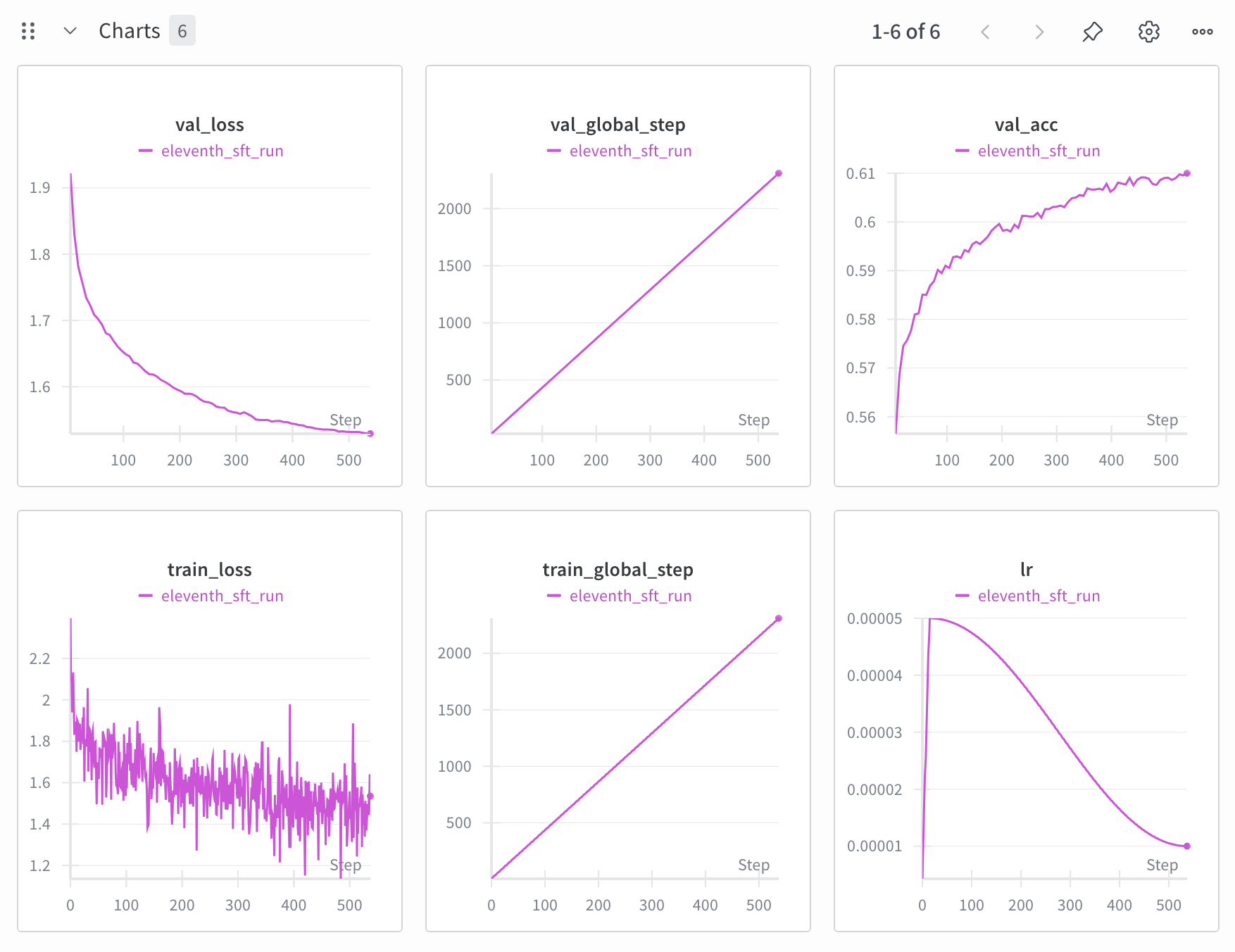
Results
Once fine-tuning was complete, it was ready to act as a chatbot, so I wrote an application to deploy on Huggingface spaces.
In the application, when a message is submitted, the entire conversation is tokenized and input into the transformer to produce the first token and fill the kv caches (prefilling), after which the kv cache is used to generate each subsequent token (decoding), which is why the first token can take longest to generate in the live demo. In the current application, every time a user submits a new message the prefill process must be started from scratch. Saving kv caches from one message submission to the next is a possible next step for my application. Other features that could be implemented include saving user conversations and implementing summarization techniques for when a conversation exceeds the context length.
In the end, I was satisfied with the performance of the model. It correctly identifies itself as CasaLLM and gives responses that correlate well to questions asked.
Nevertheless, as a 350M parameter model, it is nowhere as coherent as a larger model like the first ChatGPT was. The image below shows an example of a hallucination, which is common in this model. In the screenshot, the model describes Alpha Centauri, incorrectly referring to it as the 'Algae Star' (there is no such thing) and incorrectly saying it is a white dwarf.

The best step to create a more coherent model would be simply to train a larger one. In fact, I estimate that on a p4d.24xlarge EC2 instance, a 1.2B parameter model could be trained for around $1500. OpenAI noted that a lot of emergent behavior begins to appear as a model approaches and exceeds 1B parameters, and I may be inclined to train a larger model in the near future.